
Por primera vez, OpenAI pone a disposición de los usuarios dos modelos de código abierto que rivalizan con los mejores sistemas actuales. Son sorprendentemente fáciles de manejar, porque un usuario novato puede descargarlos, cargarlos y empezar a utilizarlos sin ninguna configuración compleja. Sin embargo, requieren un ordenador capaz de soportar su tamaño y potencia. Este artículo le ayudará a descubrir estos modelos y a hacerlos funcionar localmente en Windows.
En este artículo
OpenAI publica sus primeros modelos de peso abierto desde GPT-2
OpenAI inaugura una nueva era con la publicación de gpt-oss, una familia de modelos de peso abierto cuyos pesos pueden descargarse libremente. Esta elección contrasta con la estrategia habitual de la empresa, que desde hace varios años favorece los modelos accesibles únicamente a través de su API. Un modelo de ponderación abierta no es un modelo de código abierto en sentido estricto, ya que el código de entrenamiento y los conjuntos de datos siguen siendo privados. En cambio, las ponderaciones se ponen a disposición del público, lo que permite ejecutarlas localmente, cuantificarlas, adaptarlas a usos internos y desplegarlas sin depender de la nube.
Se trata de un acontecimiento importante, ya que OpenAI no ofrecía este nivel de acceso desde GPT-2. Por fin permite a desarrolladores, investigadores y usuarios avanzados manipular un modelo de OpenAI como cualquier otro LLM del ecosistema de código abierto, con la posibilidad de integrarlo en flujos de trabajo privados y completamente offline.
| Modelo | Talla | Material recomendado | Uso ideal |
|---|---|---|---|
| gpt-oss-20B | ≈ 21 mil millones | GPU de consumo | Se ejecuta localmente en PC con Windows o Linux |
| gpt-oss-120B | ≈ 117 mil millones | Servidores multi-GPU | Entornos profesionales |
Los primeros resultados y comentarios indican un rendimiento cercano al de o3-mini en tareas de razonamiento tradicionales. Ambos modelos se benefician de un contexto muy amplio de hasta ciento veintiocho mil tokens, lo que los hace adecuados para análisis largos, documentos complejos y agentes autónomos.
La velocidad de inferencia también es un punto fuerte del modelo 20B cuando se cuantifica y ejecuta en una GPU moderna. En comparación con modelos de referencia del mercado como LLaMA 3.1, Mixtral o Phi-3.5, gpt-oss es una de las soluciones más avanzadas en la categoría de peso abierto, al tiempo que ofrece una compatibilidad técnica muy amplia.
Uso local de modelos OpenAI con Ollama en Windows
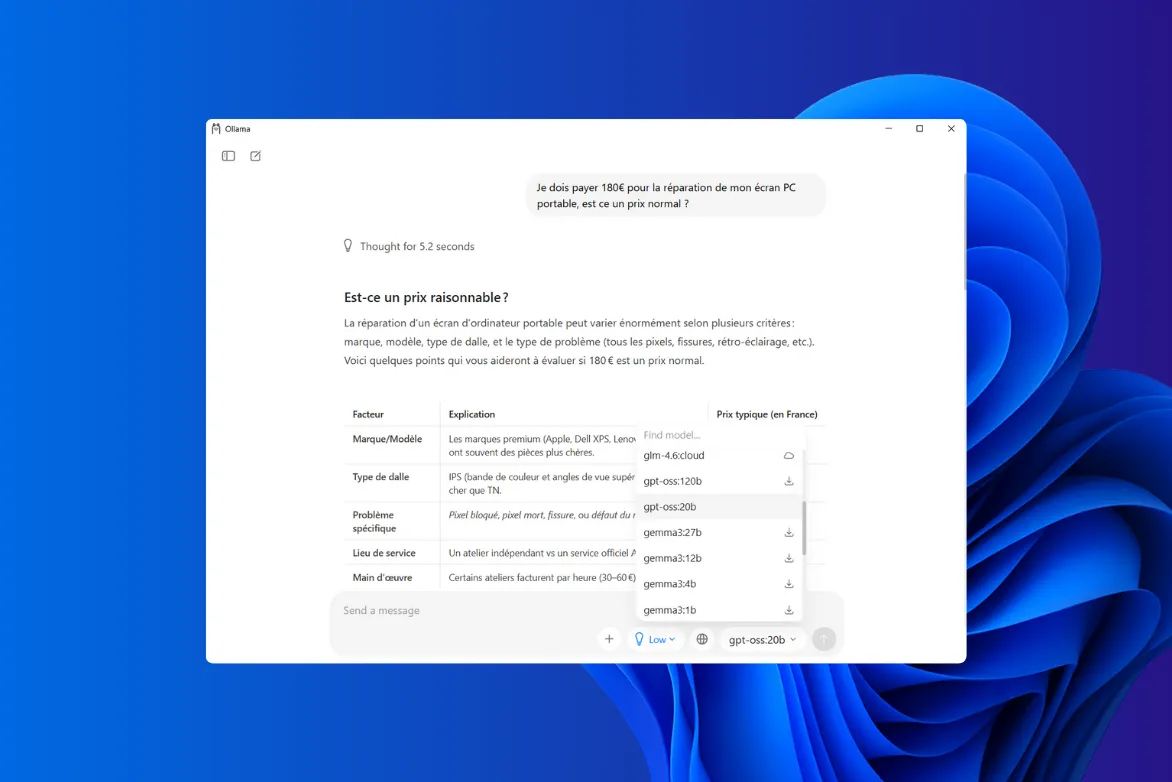
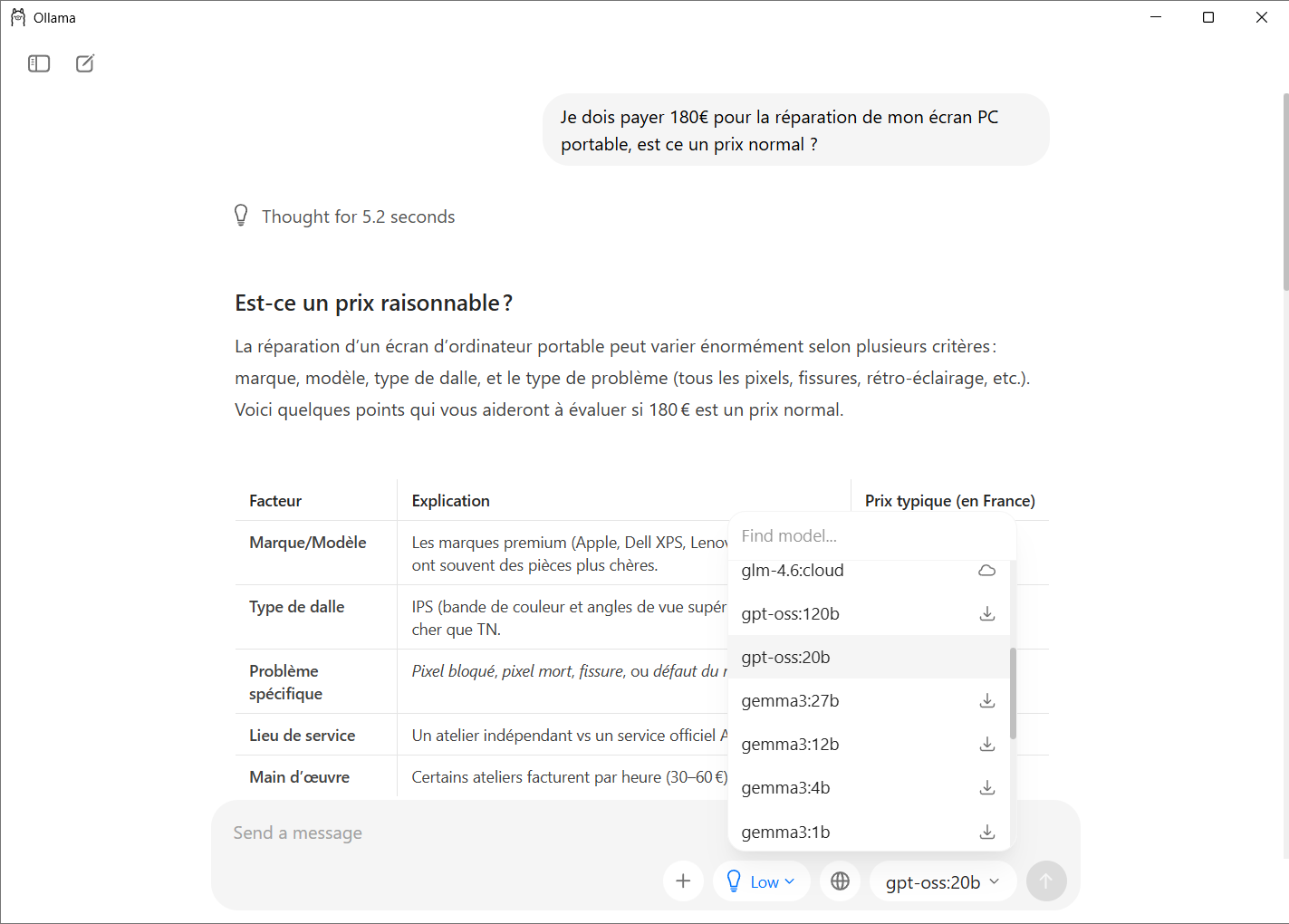
Ollama es actualmente la herramienta más sencilla y fiable para ejecutar un modelo OpenAI localmente en Windows. La aplicación cuenta con una interfaz gráfica que permite elegir, descargar y ejecutar un modelo sin ningún tipo de manipulación técnica. Los usuarios sólo tienen que seleccionar un modelo de la lista, hacer clic para instalarlo y empezar a conversar con él en una ventana al estilo de ChatGPT.
Los scripts, aplicaciones y herramientas diseñados para ChatGPT pueden funcionar exactamente igual, simplemente apuntando a la dirección local proporcionada por Ollama. Por lo tanto, no es necesario modificar su código ni sus automatizaciones. Para el uso diario, no se requiere línea de comandos, lo que hace que la experiencia sea accesible incluso para un usuario novato.
- Para utilizarlo, basta con visitar el sitio web oficial de Ollama y descargar el instalador para Windows.
- Una vez iniciado, el asistente configura automáticamente todos los elementos necesarios e instala el servicio en segundo plano para cargar los modelos a petición.
Tras la instalación, Ollama crea una carpeta dedicada en el perfil del usuario para almacenar los modelos descargados. Esta carpeta se encuentra en el directorio personal, lo que facilita su gestión o la eliminación de pesos en caso necesario. Ollama incluye un catálogo de modelos al que se puede acceder directamente desde su interfaz.
- Para descargar gpt-oss, sólo tiene que abrir la aplicación y seleccionar el modelo que desee de la lista.
La herramienta recupera automáticamente los archivos necesarios y los instala sin intervención manual. Una vez que el modelo está presente en la máquina, aparece inmediatamente como disponible en la interfaz.
Se utiliza en el mismo campo de entrada que un chatbot tradicional. Puedes escribir una pregunta o ajustar ciertos parámetros. La experiencia es muy similar a la de ChatGPT, pero totalmente offline.
Si los usuarios quieren realizar búsquedas web directamente desde la interfaz de Ollama o utilizar extensiones que requieren conexión a Internet, necesitan activar una función en la nube.
Ejecución local: rendimiento y hardware recomendado
La ejecución local de los modelos gpt-oss depende en gran medida de la configuración del hardware y de la cantidad de VRAM disponible. Cuanto mayor sea la VRAM, más se podrá cargar el modelo directamente en la GPU, lo que mejora considerablemente la velocidad de inferencia y la estabilidad. Cuando un modelo no cabe por completo en la GPU, Ollama cambia automáticamente parte de la carga a la RAM. Esta solución permite ejecutar modelos más grandes que la memoria de vídeo disponible, pero aumenta el tiempo de respuesta y puede provocar errores o imprecisiones cuando el voltaje de la memoria es demasiado alto.
Los requisitos varían mucho entre gpt-oss-20B y gpt-oss-120B. El primero puede ejecutarse en un PC gamer reciente gracias a las cuantificaciones, mientras que el segundo está reservado a infraestructuras profesionales con varias decenas de gigabytes de VRAM.
| Modelo | FP16 | Q8 | Q5 | Q4 |
|---|---|---|---|---|
| gpt-oss-20B | 30-40 GB | 18-22 GB | 10-12 GB | 8 GB |
| gpt-oss-120B | 150+ GB | 90 GB | – | – |
Si tu PC no es lo suficientemente potente, existen modelos más adecuados. Infórmate sobre los mejores modelos y software para ejecutar IA local en Windows.
La ejecución local puede mejorarse significativamente aplicando algunas buenas prácticas, especialmente cuando la VRAM no es óptima.
Elegir la cuantización Q4 en una GPU pequeña
Este formato ofrece uno de los mejores compromisos entre velocidad y calidad. Permite que gpt-oss-20B quepa en una tarjeta gráfica de gama media manteniendo un nivel aceptable de precisión. Por debajo de Q4, los errores son más frecuentes y el modelo puede producir incoherencias.
Favorecer la GPU frente a la CPU
Aunque Ollama puede utilizar la RAM y la CPU para completar la carga, el rendimiento cae rápidamente en cuanto el modelo abandona la VRAM. Cuanto más soporte la GPU todos o la mayoría de los pesos, más rápida, estable y fiable será la generación.
Uso de multi-GPU en Linux para modelos gigantes
El modelo gpt-oss-120B requiere un entorno multi-GPU o un servidor con una VRAM extremadamente alta. En Linux, la distribución automática de los bloques del modelo entre varias tarjetas gráficas permite utilizar este tipo de modelo en un entorno profesional.