For the first time, OpenAI is making available two open-source models that rival today’s best systems. They are surprisingly easy to get to grips with, as a novice user can now download, load and start using them without any complex configuration. They do, however, require a computer with the muscle to handle their size and power. This article will help you discover these models and get them running locally on Windows.
Using ChatGPT-OSS locally with OpenAI’s open-weight templates
- OpenAI publishes its first open-weight models since GPT-2
- Using OpenAI templates locally with Ollama on Windows
- Local execution: performance and recommended hardware
OpenAI publishes its first open-weight models since GPT-2
OpenAI ushers in a new era with the release of gpt-oss, a family of open-weight models whose weights are freely downloadable. This choice contrasts with the company’s usual strategy, which for several years has favored models accessible only via its API. An open-weight model is not an open-source model in the strict sense, as the training code and data sets remain private. Weights, on the other hand, are made available to the public, enabling local execution, quantification, adaptation to internal uses and deployment without dependence on the cloud.
This is a major event, as OpenAI has not offered this level of access since GPT-2. It finally enables developers, researchers and advanced users to manipulate an OpenAI model like any other LLM in the open-source ecosystem, with the possibility of integrating it into private, totally off-line workflows.
| Model | Size | Recommended material | Ideal use |
|---|---|---|---|
| gpt-oss-20B | ≈ 21 billion | Consumer GPU | Runs locally on Windows or Linux PCs |
| gpt-oss-120B | ≈ 117 billion | Multi-GPU servers | Professional environments |
Initial results and feedback indicate performance close to that of o3-mini for classical reasoning tasks. Both models benefit from a very large context of up to one hundred and twenty-eight thousand tokens, making them suitable for long analyses, complex documents and autonomous agents.
Inference speed is also a strong point for the 20B model when quantized and run on a modern GPU. Compared with market reference models such as LLaMA 3.1, Mixtral or Phi-3.5, gpt-oss is one of the most advanced solutions in the open-weight category, while offering very broad technical compatibility.
Using OpenAI templates locally with Ollama on Windows
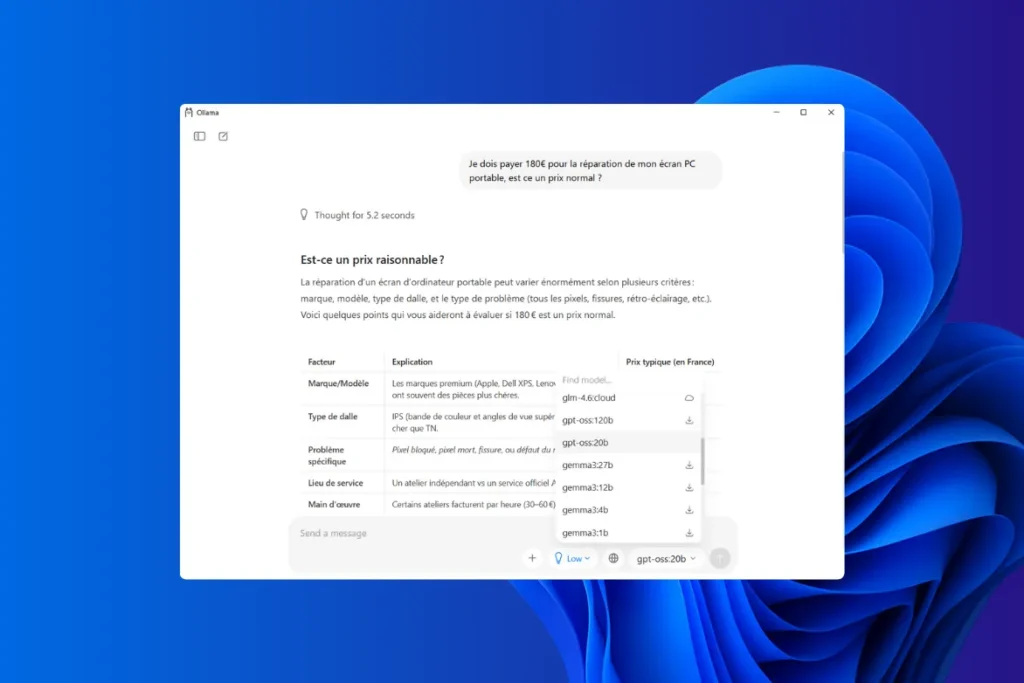
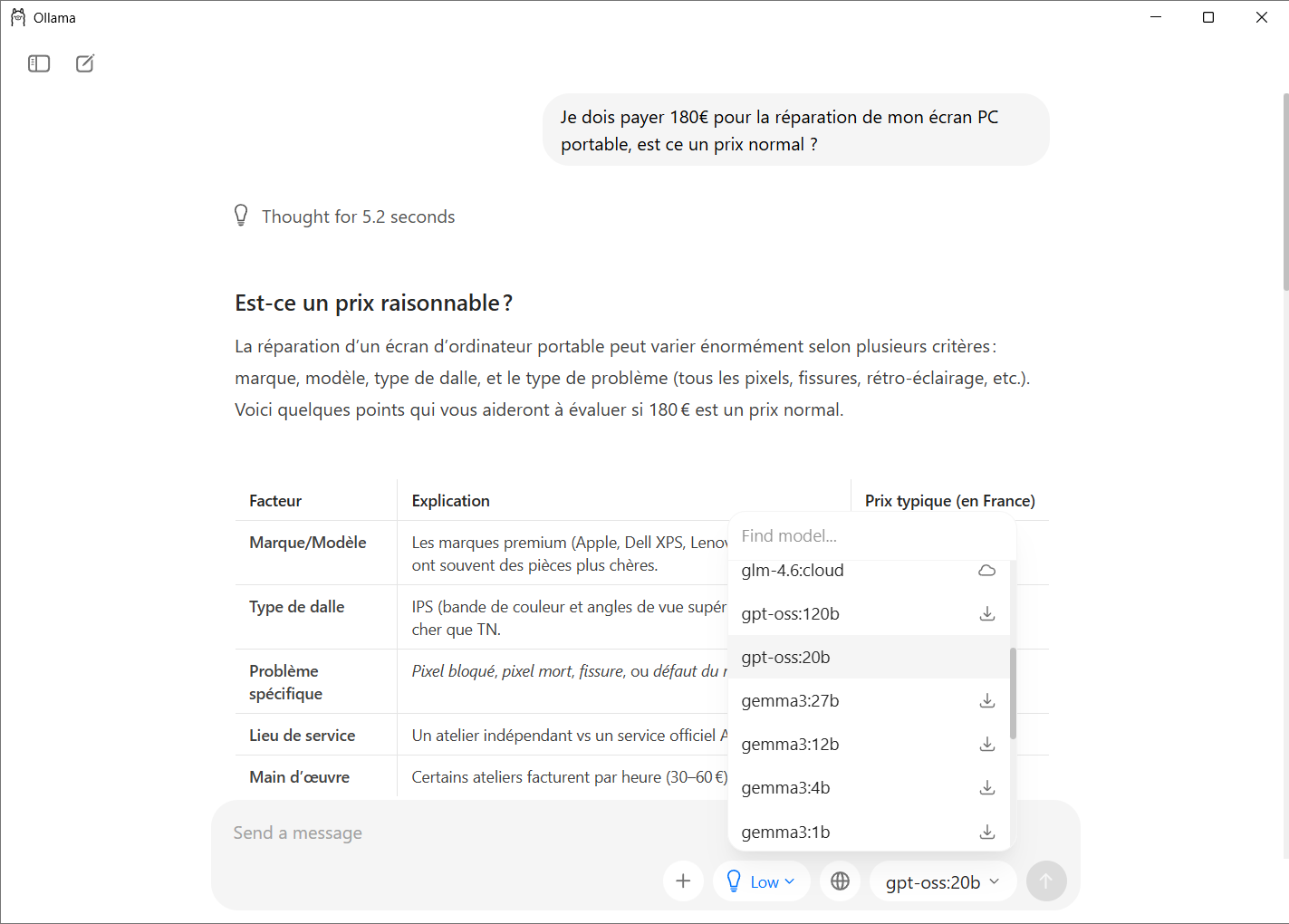
Today, Ollama is the simplest and most reliable tool for running an OpenAI model locally on Windows. The application features a graphical interface that lets you choose, download and run a template without any technical manipulation. Users simply select a template from the list, click to install it and start chatting with it in a ChatGPT-style window.
Scripts, applications and tools designed for ChatGPT can operate in exactly the same way, simply by pointing to the local address provided by Ollama. So there’s no need to modify your code or automations. For everyday use, no command line is required, making the experience accessible even to a novice user.
- To use it, simply visit the official Ollama website and download the Windows installer.
- Once launched, the wizard automatically configures all the necessary elements and installs the background service that will load the templates on demand.
After installation, Ollama creates a dedicated folder in the user profile to store downloaded models. This folder is located in the user’s personal directory, making it easy to manage or delete weights if necessary. Ollama integrates a catalog of templates directly accessible from its interface.
- To download gpt-oss, simply open the application and select the desired model from the list.
The tool automatically retrieves the necessary files and installs them without manual intervention. Once the model is present on the machine, it immediately appears as available in the interface.
You can use the same input field as a traditional chatbot. You can type a question or adjust certain parameters. The experience is very similar to that of ChatGPT, but entirely offline.
If users wish to carry out web searches directly from the Ollama interface, or use extensions that require an Internet connection, they need to activate a cloud function.
Local execution: performance and recommended hardware
Local execution of gpt-oss models is highly dependent on hardware configuration and the amount of VRAM available. The higher the VRAM, the more the model can be loaded directly onto the GPU, which considerably improves inference speed and stability. When a model doesn’t fit entirely on the GPU, Ollama automatically switches part of the load to RAM. This solution makes it possible to run models larger than the available video memory, but it increases response time and can lead to errors or inaccuracies when the memory voltage becomes too high.
Requirements vary widely between gpt-oss-20B and gpt-oss-120B. The former can run on a recent gamer PC thanks to quantisations, while the latter is reserved for professional infrastructures with several tens of gigabytes of VRAM.
| Model | FP16 | Q8 | Q5 | Q4 |
|---|---|---|---|---|
| gpt-oss-20B | 30-40 GB | 18-22 GB | 10-12 GB | 8 GB |
| gpt-oss-120B | 150+ GB | 90 GB | – | – |
If your PC isn’t powerful enough, there are more suitable models. Discover the best models and software for running a local AI on Windows.
Local execution can be significantly improved by applying a few best practices, especially when VRAM is not optimal.
Choosing Q4 quantization on a small GPU
This format offers one of the best compromises between speed and quality. It allows gpt-oss-20B to fit on a mid-range graphics card while maintaining an acceptable level of accuracy. Below Q4, errors become more frequent and the model may produce inconsistencies.
Favoring the GPU over the CPU
Although Ollama can use RAM and CPU to complete the load, performance drops off rapidly as soon as the model leaves VRAM. The more the GPU supports all or most of the weights, the faster, more stable and more reliable the generation will be.
Using multi-GPU under Linux for giant models
The gpt-oss-120B model requires a multi-GPU environment or a server with extremely high VRAM. Under Linux, the automatic distribution of model blocks between several graphics cards enables this type of model to be used in professional environments.
Did you find this article helpful?
Share it so others can benefit from it.
Learn more about the author