L’intelligence artificielle impressionne, mais toutes ne se valent pas. Dans un test de QI comparatif récemment publié, plusieurs modèles linguistiques ont été évalués pour mesurer leur capacité à raisonner logiquement, comprendre des analogies ou résoudre des problèmes abstraits. Surprise : Microsoft Copilot arrive parmi les derniers du classement. Une performance décevante qui questionne la réelle maturité de l’outil… malgré sa forte intégration dans l’écosystème Windows.
Benchmark QI des IA : un test sans Internet basé sur le raisonnement
Pour évaluer les véritables capacités cognitives des modèles linguistiques, les chercheurs à l’origine du test ont volontairement écarté toute question basée sur des faits indexables ou des données mémorisées. Exit les connaissances encyclopédiques ou les réponses issues du web : ce benchmark s’appuie uniquement sur des questions de raisonnement logique, conçues pour mesurer la capacité d’une IA à déduire, anticiper ou compléter un raisonnement abstrait.
Le format est directement inspiré des tests d’admission de type Mensa ou SAT, avec des suites logiques, des analogies, des puzzles verbaux ou mathématiques, mais sans aucun recours possible à l’Internet ou à des bases de données préentraînées. L’objectif : ne pas juger ce que l’IA sait, mais ce qu’elle comprend et infière en temps réel.
Une grille de notation entre 55 et 145
Le score attribué à chaque modèle suit une échelle de quotient intellectuel calquée sur celle des humains, comprise entre 55 (faible) et 145 (hautement supérieur). Un score de 100 correspond au niveau moyen attendu chez un adulte humain.
Chaque IA a été testée en conditions identiques, sans assistance contextuelle ni accès externe à Internet. Cela permet d’obtenir une base de comparaison fiable entre les différents modèles, qu’il s’agisse d’IA grand public comme ChatGPT, de modèles open source comme Mistral, ou de solutions intégrées comme Microsoft Copilot.
Ce protocole strict met en lumière des différences profondes entre les architectures d’IA, en particulier sur leur capacité à simuler un raisonnement logique autonome, sans support ni contexte externe.
Résultats du test : Copilot en queue de peloton
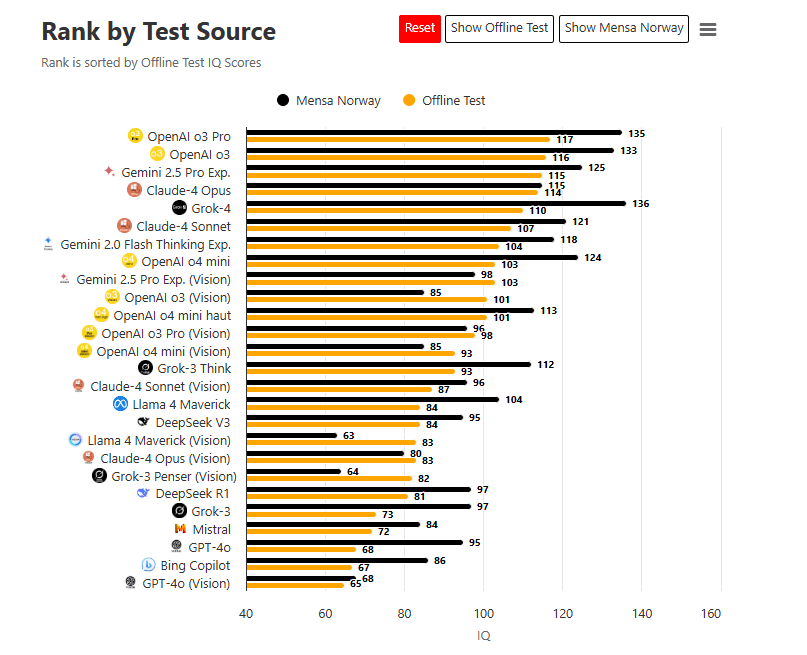
Le verdict est sans appel : Microsoft Copilot se classe 25e sur 26 modèles d’intelligence artificielle testés. En mode autonome (hors ligne), il n’a obtenu qu’un score de 67, ce qui correspond à un niveau nettement inférieur à la moyenne humaine. Même lors du test Mensa norvégien, son score plafonne à 84, loin derrière les ténors du classement.
À titre de comparaison :
- Grok-4 (xAI/Elon Musk) atteint 136,
- Claude 3 Opus (Anthropic) culmine à 131,
- OpenAI o3 Pro (alias GPT-4o) se positionne à 117.
Ce classement est d’autant plus surprenant que Copilot repose partiellement sur les modèles d’OpenAI GPT-4 dans certains cas. Comment expliquer une performance aussi faible alors qu’il est censé bénéficier des meilleurs moteurs disponibles ?
Plusieurs hypothèses émergent :
- En mode hors ligne ou entreprise, Copilot ne semble pas exploiter GPT-4 intégralement, mais plutôt une version allégée ou bridée.
- Son intégration à Microsoft 365 priorise les tâches bureautiques et les réponses pratiques, au détriment du raisonnement abstrait ou logique.
- Certaines limitations techniques (filtrage, latence, priorité à la sécurité) peuvent altérer ses performances brutes sur ce type de test.
La contre-performance ne signifie pas que Copilot est inutile mais elle souligne qu’en dehors des scénarios Microsoft, l’outil a peu de marge face aux leaders de l’intelligence générale.
Vous avez trouvé cet article utile ?
Partagez-le pour en faire profiter d'autres.