
Artificial intelligence is impressive, but not all models are created equal. In a recently published IQ benchmark test, several language models were evaluated based on their ability to reason logically, understand analogies, and solve abstract problems. The surprise? Microsoft Copilot ranked near the bottom. A disappointing performance that raises questions about the tool’s true maturity, despite its deep integration within the Windows ecosystem.
Microsoft Copilot among the worst language models according to an IQ test
- AI IQ Benchmark: an Internet-free test based on reasoning
- Test results: Copilot at the back of the pack
AI IQ Benchmark: an Internet-free test based on reasoning
To assess the true cognitive capabilities of linguistic models, the researchers behind the test have deliberately excluded any questions based on indexable facts or memorized data. Out go encyclopedic knowledge or answers taken from the web: this benchmark relies solely on logical reasoning questions, designed to measure an AI’s ability to deduce, anticipate or complete abstract reasoning.
The format is directly inspired by Mensa or SAT-type admission tests, with logical sequences, analogies, verbal or mathematical puzzles, but without any possible recourse to the Internet or pre-trained databases. The aim is not to judge what the AI knows, but what it understands and infers in real time.
A rating grid between 55 and 145
The score assigned to each model follows an IQ scale modelled on that of humans, ranging from 55 (low) to 145 (highly superior). A score of 100 corresponds to the average level expected of a human adult.
Each AI has been tested under identical conditions, without context-sensitive assistance or external Internet access. This provides a reliable basis for comparison between the different models, whether they are consumer AIs like ChatGPT, open source models like Mistral, or integrated solutions like Microsoft Copilot.
This strict protocol highlights profound differences between AI architectures, in particular their ability to simulate autonomous logical reasoning, without external support or context.
Test results: Copilot at the back of the pack
The verdict is clear: Microsoft Copilot ranks 25th out of 26 artificial intelligence models tested. In stand-alone mode (offline), it scored just 67, well below the human average. Even in the Norwegian Mensa test, its score plateaued at 84, far behind the leading contenders.
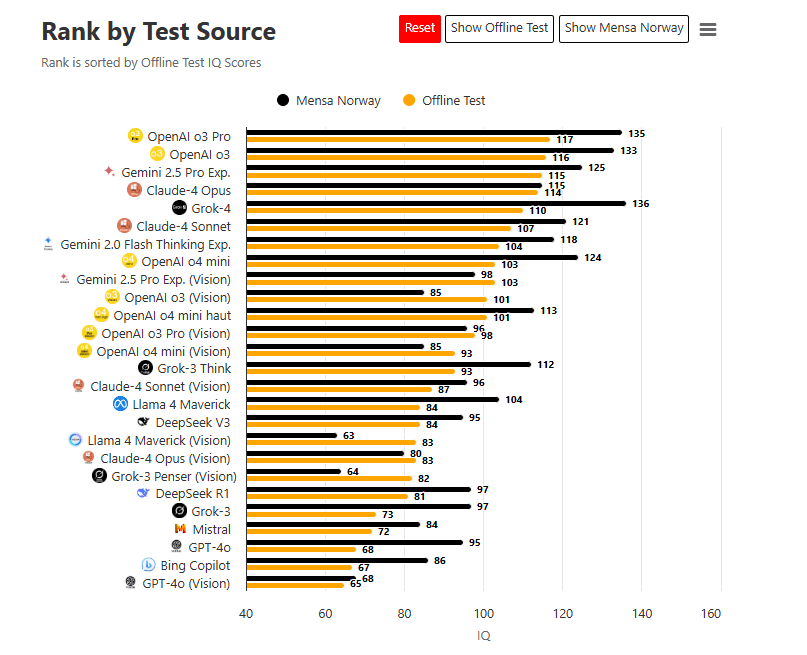
By way of comparison :
- Grok-4 (xAI/Elon Musk) reaches 136,
- Claude 3 Opus (Anthropic) peaks at 131,
- OpenAI o3 Pro (aka GPT-4o) is positioned at 117.
This ranking is all the more surprising given that Copilot is partially based on OpenAI GPT-4 models in some cases. How can such poor performance be explained when it is supposed to benefit from the best engines available?
Several hypotheses emerge:
- In offline or enterprise mode, Copilot doesn’t seem to use GPT-4 in its entirety, but rather a lightened or restricted version.
- Its integration with Microsoft 365 prioritizes office tasks and practical answers, to the detriment of abstract or logical reasoning.
- Certain technical limitations (filtering, latency, security priority) may alter its raw performance on this type of test.
This underperformance doesn’t mean Copilot is useless, but it does underline the fact that, outside Microsoft scenarios, the tool has little margin against the leaders in general intelligence.
Did you find this article helpful?
Share it so others can benefit from it.
Learn more about the author
